Mar 11
2026
Why frontier models can't pilot robots (yet)
Why frontier models can't reliably pilot our robots, and why we're training purpose-built models instead.
Vitrus is an AI-first company. We use AI coding tools throughout our workflow, and we've built harnesses that let AI help us with CAD, design robots, and model scenes. We love frontier models — Claude, Codex, and Gemini are all part of how we work day to day.
So when it came time to make our robots intelligent, we did the obvious thing first: before hiring anyone to train AI, before committing to the VLA and world-model approaches the rest of the industry has converged on, we wanted to see how far we could get by just plugging frontier models into the loop with good prompting. If the models we already love working with could operate robots directly, that would be a much simpler path.
The answer, it turns out… is that they can't.

What frontier models can do
We set up a clean evaluation: good ambient light, global shutter cameras, 3D tracking markers — the basics done right. Then we gave OpenAI and Gemini models full agentic control over the robot, with visual input on a loop and prompts asking them to perform manipulation tasks.
Spatial reasoning and scene understanding were genuinely impressive. The models can look at a scene, identify objects, and describe relationships between them with reasonable accuracy. They've gotten dramatically better at this over the past year. (Though in other work we've run into surprising failures around multi-view reasoning and 3D relationships — the capability is real but uneven.)
Gemini outperformed OpenAI's models on these tasks, for what it's worth.
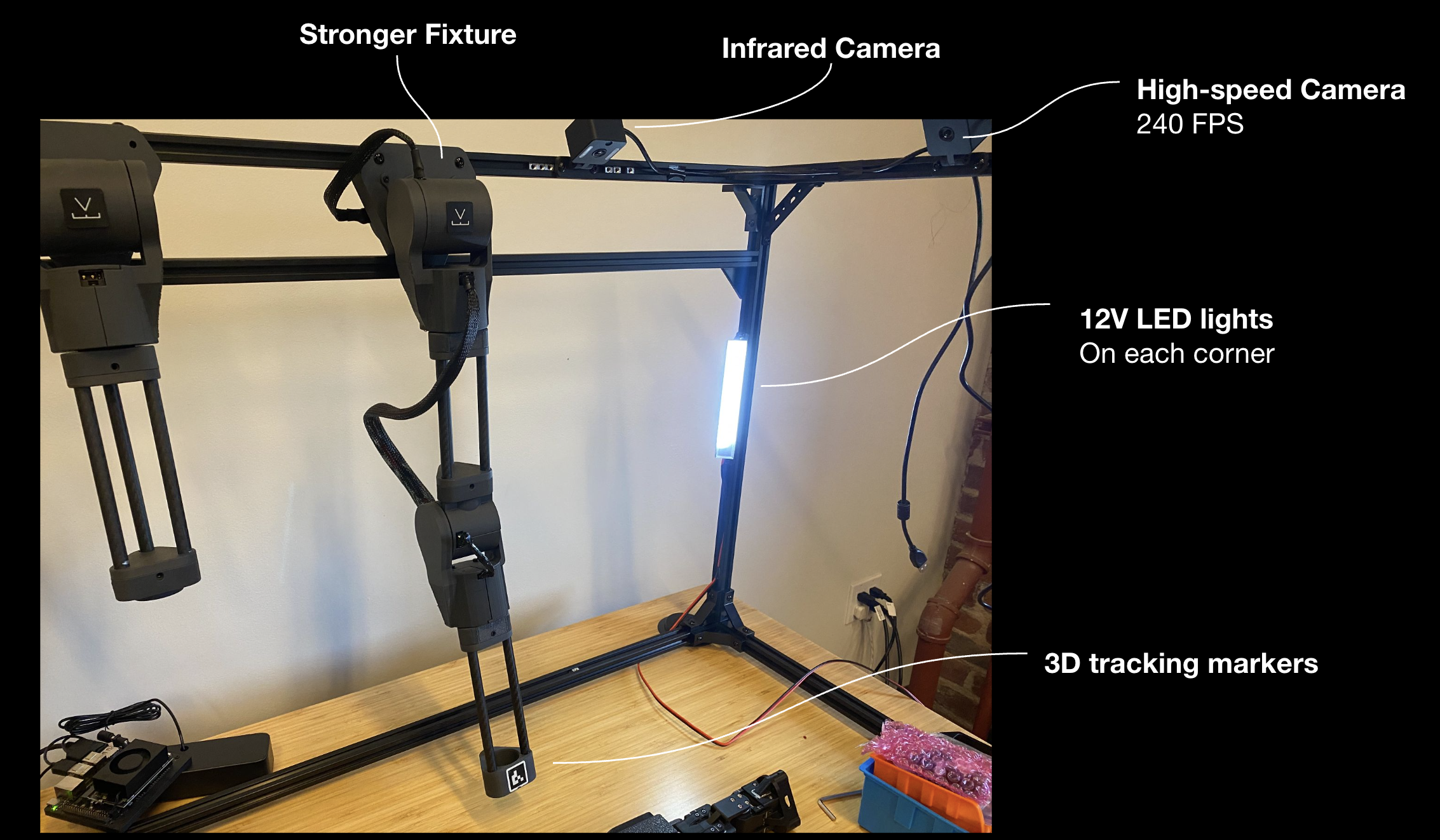
Where they break down
Two problems showed up immediately, and neither is the kind of thing a better prompt can fix.
They're too slow. Imagine trying to pick up a wooden block, but you can only open your eyes once every ten seconds. That's roughly the perceptual window a frontier model gives you in a control loop. The robot is effectively blind between inferences, and the quality of motion collapses as a result. You can do crude gestures — a wave, a rough reach — but anything requiring precision falls apart.
They can't plan trajectories. This is the deeper problem. Even when we gave the models the full history of what the robot had been doing, plus current visual input, they couldn't figure out how to pilot the arm through a coherent motion. They lack a native understanding of trajectories and embodiment. They know what should happen in the scene; they don't know how to make their body do it.

Why we're training our own models
This was a useful exercise. We learned what the ceiling looks like for the prompted-frontier-model approach, and we now have strong evidence for what the rest of the robotics industry has been finding: reliable robot intelligence has to be trained, not prompted into existence.
So we're now training our own models — built to handle contact-rich manipulation, the specific factory tasks our users actually need done, and the embodiment of the robots we're building. Understanding embodiment well enough to produce usable trajectories is beyond what any prompting harness can extract from a general-purpose model. And you can't get the speed you need for real control without the architectural choices that come with a purpose-built robot model.
Everything shown here was built between August and December 2025. More from our 2026 work soon.