
Modeling Physical Motion with AI
Vitrus mission is to accelerate the built world. The key critical path for that is efficient fabrication and maintenance.
Vitrus is my “thank you letter” to Buckminster Fuller a designer that was able to perceive and create structures like no other before, across scales.

Getting Physical: where frontier AI models fail
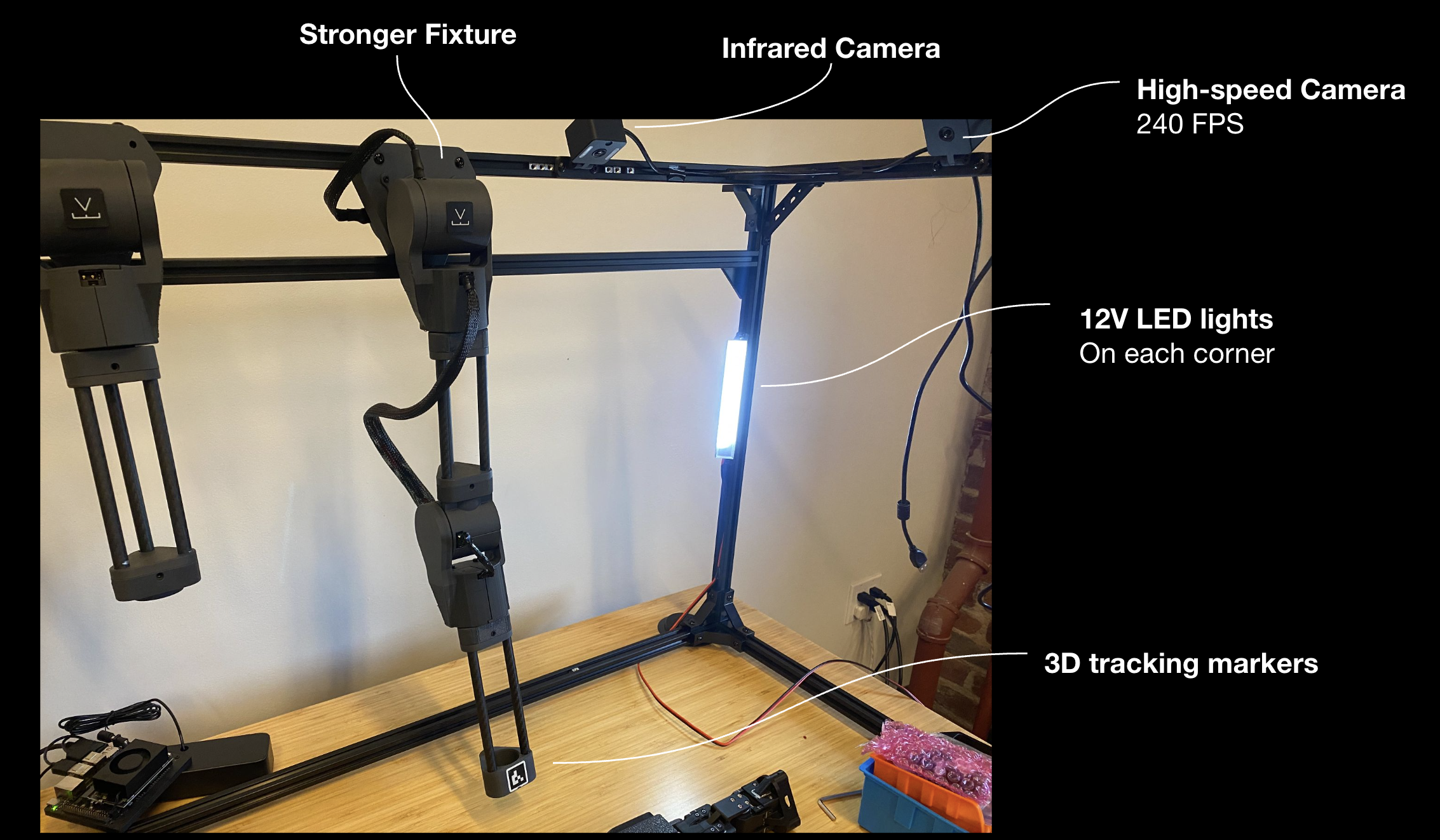
First setup to evaluate how OpenAI and Gemini models would understand physical reality and motion planning.
We covered the basics: good ambient light, global shuttering cameras, 3D tracking markers: this is the basics. So we gave that complete access to frontier models with agentic behavior to control these.
Frontier models presented great spatial reasoning and perception, however they were really weak in object trajectory modeling and overall motion planning.
They can do the basics, like wave.. but still lack precision and detailed motion to pick up something.
Extremely Slow
Gemini Performed better than OpenAI
Weak motion planning

Frontier Models are too slow.
Imagine you need to pick up a wooden block, but you’re only able to open your eyes once every 10 seconds… your window into perceiving reality would be tiny, diminishing your quality of movement.

Because of those issues we’re now training our new generation of Vitrus models with a deeper perception of reality.

There are so many details that would make this first blog post too convoluted, I believe images (GIFs) are better to illustrate these problems we’re facing, and also shows a bit of our design.
Everything you saw here we built between August 2025 and December 2025.
We will be showing more of our 2026 work in an upcoming release.